






Modeling Technique Simplifies Optimization Of Complex Waterfloods
By Jeremy Viscomi and Carlos Calad
Optimizing waterfloods can be complex and time-consuming. Ideally, optimization will begin at the design stage before the well spuds. However, most waterfloods in the Lower 48 have been in operation for many years. Because it is so difficult to model these fields, optimization efforts generally rely on consultants or the long-term experience of staff engineers and geologists. They also rarely consider reservoir conditions across the entire field.
Big data, machine learning and artificial intelligence can make more comprehensive optimization efficient and affordable, but these digital buzzwords have been applied so widely that they mean little by themselves. Potential users must distinguish between machine learning programs that merely provide access to data and solutions that analyze data to guide decisions.
The most effective solutions use an approach called “data physics,” which involves applying machine learning algorithms to historical data but constraining their inputs to ensure they honor the laws of physics. Data physics has proven so effective in waterfloods and other applications that it is getting attention from operators and service companies large and small. They recognize that it offers a fast but accurate way to optimize production.
Traditional Approaches
In traditional reservoir management, including waterflood design and optimization, various predictive models can be applied to enable quantitative decision-making. These models range from simple type curves to extremely complex numerical reservoir simulations. The simulations account for detailed reservoir physics and integrate all kinds of measured data, so they can produce accurate predictions. However, building and calibrating simulation models takes significant time and effort, which makes applying them challenging.
Also, the detail that gives simulations their accuracy comes with the downside of computational complexity. It takes enough computing power and time to run the models that engineers must carefully select which scenarios they want to evaluate.
In contrast, machine learning algorithms can provide answers quickly and are easy to set up. Unfortunately, because they rely on analyzing trends in historical data rather than applying the laws of physics (e.g., equations governing how fluids move through porous media), their predictions lack robustness, which limits their applicability to short time periods.
To provide both speed and accuracy, data physics melds state-of-the-art machine learning with the physics present in industry-standard reservoir simulators. Data physics models can be created as efficiently as machine learning models and evaluated orders of magnitude faster than full-scale simulations, but because they honor physics and integrate all kinds of data, they can make accurate long-term predictions.
In waterflood applications, data physics enables users to move from data preparation and modeling to effective decision-making in a matter of days rather than months or even years. In addition, the models can be updated with new data quickly, so they always remain operationally useful.
Quantitative Optimization
Data physics offers a framework in which petroleum engineers can optimize a reservoir’s oil production quantitatively. It shows engineers which daily, weekly or monthly actions will maximize returns by investigating tens of thousands of scenarios that simulate specific activities (e.g., increasing injection or changing drilling programs). This allows engineers to select plans that meet specific optimization criteria, such as preserving production rates or optimizing long-term reserves growth.
Sometimes engineers need to optimize multiple criteria simultaneously. To achieve this goal, engineers must have an accurate and statistically proven predictive model of reservoir mechanisms. They must be able to predict not only well-by-well behavior, but also correctly analyze well and pattern interdependencies. In each case, the physics must drive the predicted outcome, and statistical confidence must be calculated so that relative risk can be accounted for.
To this end, data physics merges modern data science and the physics of reservoir simulation. Data physics models, like machine learning ones, require only days to set up and can be run in real time. Because they include the same physics as a reservoir simulation, they offer excellent long-term predictive capacity even when historical data is sparse, missing or noisy.
At their core, data physics models are physics-based models augmented by machine learning techniques; the underlying reservoir physics equations are solved continuously across the reservoir, which limits the machine learning algorithms’ solutions to those that are consistent with reservoir physics. While one of the techniques used to calculate coefficients in some of these equations is inspired by neural networks, the models always are constrained to honor both the underlying system’s physical equations and the actual measured data.
This approach differs dramatically from traditional machine learning, which does not attempt to constrain models using the governing physics. Purely data-driven approaches such as neural networks only utilize input-output behavior present in training data and do not involve any actual physical equations. Many of these methods incorrectly assume the neural network will “learn” the equations. Instead, it often generates a solution that is physically implausible or impossible, or makes inaccurate predictions when it is presented with a situation its training data did not anticipate.
Data Physics’ Role
Data physics models resemble traditional simulation more than neural networks, but they have the added capability to adapt to cases where the physics are poorly understood. Also, data physics’ intent differs from traditional reservoir simulation. Because the models focus on predicting how specific activities will impact production–not characterizing the reservoir–they can be designed to operate quickly and to explore millions of scenarios.
This speed permits the models to be validated against production history and tuned constantly. Such tuning allows the models’ accuracy to be quantified statistically across several scenarios, enabling engineers to evaluate the risk associated with each one.
Data physics can replace traditional reservoir simulators for tasks that require a geomodel with a high degree of accuracy. Because data physics defines accuracy to mean “does the model correctly predict oil production in a certain scenario?” the models it produces excel at forecasting production and are easily re-run with real-time field and production data.
Having said that, tasks that require a full geomodel likely will continue to rely on existing simulations. For example, understanding geologic scenarios or drive mechanisms, screening enhanced oil recovery methods and making greenfield development decisions generally will still require current simulation methods because data physics models need historical data from the field that would not yet be available in those situations.
Unlike traditional sequential reservoir simulation workflows, data physics models can integrate production data, log data and seismic data in a single assimilation step. These models directly incorporate raw data such as log responses without manual interpretation, and can assimilate various forms of data without inconsistencies. These capabilities are one reason the models can be built rapidly and updated continuously.
Implementation
To make it easy for engineers to apply data physics to waterfloods, a Web-based application has been created. This application generates a Pareto Front plot in which the x axis represents a percentage decrease in injection over the time frame considered and the y axis represents the percentage of incremental oil production (Figure 1).
FIGURE 1
A Pareto Front Showing How Injection Changes Impact Production
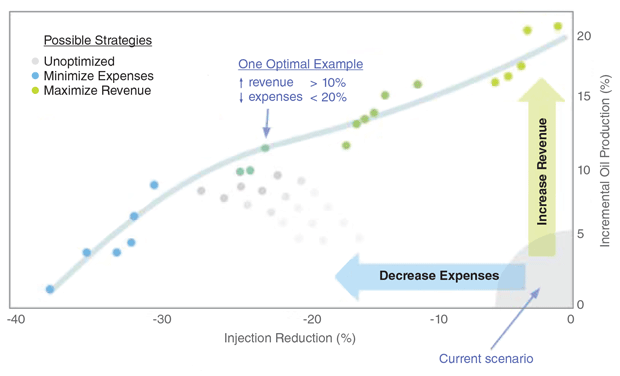
The plot is designed to help operators determine the optimal way to reduce or redistribute injection water quickly. It shows that as injection expense increases, revenue rises but net profit shrinks. Reduce injection expenses 40%, and expenses drop dramatically, but so does revenue. One optimal example shows an injection reduction of 20% with an increase in revenue of 10%.
As documented in SPE-203046, data physics has been successfully applied in Argentina to create predictive models by layer in a multilayer mature waterflood. This project showed that the technology can generate reliable predictions in complex, multilayered fields, the very type of field where most U.S. waterfloods take place.
The predictive models were used to calculate optimum scenarios that would increase production significantly and net present value if implemented. The application also modeled injection reactivation and generated an optimum implementation schedule that provided both the right order to reactivate and the optimum injection rates for each injector.
Finally, the application identified which injectors not to reactivate. In other words, it showed which wells would not generate enough additional production to justify the reactivation cost, which was estimated at $350,000 for each well.
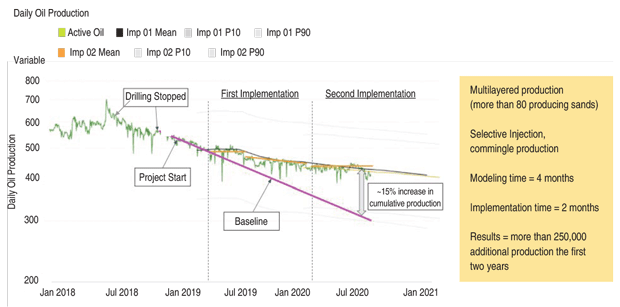
Figure 2 shows one of the key outcomes from using data physics. Notice that the decline curve flattens after first and second implementation of optimization processes. Following its completion, the well was showing a consistent decline. After the first optimization, production began to improve, and after the second optimization, production stayed relatively steady. The optimizations increased cumulative production across a two-year period by 15%, unlocking 25,000 additional barrels.
FIGURE 2
Sample Uplift from Aqueon Data Physics
Continuous Improvement
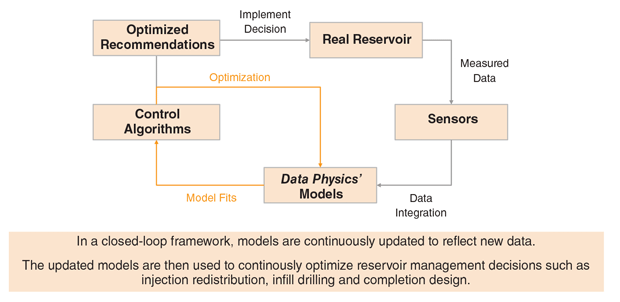
Data physics is a closed loop process where models are updated continuously to reflect new data (Figure 3). Those models then are used to continuously optimize reservoir management decisions, such as injection redistribution, infill drilling and completion design.
The Web-based application that implements data physics can help U.S. operators leverage fast optimization algorithms to mitigate risk and determine the best possible use of capital. By deploying it, engineers can explore millions of scenarios rapidly rather than sifting through vast datasets manually. This frees them to focus on managing the trade-offs between cutting costs, increasing oil production, and maximizing recovery across a range of operational and development plans.
FIGURE 3
Data Physics Closed Loop Optimization
The application also helps operators with descriptive analytics, giving engineers several ways to visualize past pattern performance, potential water redistribution plans and expected drilling response.
Data physics has been used to model thousands of injection rate modifications and infill drilling opportunities. Predicted financial impact has been validated across more than a dozen fields. On average, producers can cut the water oil ratio by 10%, saving tens of millions of dollars on water cycling each year while achieving better than 10% increases in oil production.

JEREMY VISCOMI is a strategic marketing expert for the oil and gas industry. Among his many roles, he serves as the Mid-Continent regional lead for the Petroleum Technology Transfer Council, providing independent operators with access to emerging technology aimed at reducing risk and growing profits. Viscomi also is principal owner of PIKA Industries Consulting. He graduated from the University of Kansas with a BA in English and Marketing.

CARLOS CALAD is senior vice president of global business operations at Tachyus. Before joining the company, Calad was the chief operating officer at Lupatech, the largest Brazilian oil field services company. He has served as vice president of marketing at Archer and held management, commercial and technical roles across Schlumberger. Calad holds a BS in Electrical Engineering from the Universidad de Los Andes and has completed post-graduate studies at Harvard, Columbia and Stanford.
For other great articles about exploration, drilling, completions and production, subscribe to The American Oil & Gas Reporter and bookmark www.aogr.com.