






AI Assistants Free Engineering Teams, Enhance Productivity And Innovation
By Shankar Narayanan
Picture a production engineer at a central facility in the Permian Basin, juggling dozens of tasks before sunrise. One well is underperforming. Another needs a workover decision. Data is scattered across spreadsheets, SAP, PDFs and field logs. Sound familiar? Now imagine having an assistant that reads every well file, analyzes SCADA signals, understands historical production behavior, checks parts inventory, drafts a recommendation, and emails a summary to the operations lead—before the second cup of coffee.
This is not science fiction. This is the power of generative AI and its emerging evolution: agentic AI.
Traditional AI and machine learning systems are trained to detect patterns in structured data—think predictive models for equipment failure based on sensor readings. Generative AI, or GenAI, is different. It uses “foundation models” trained on massive datasets (including text, images and programming code) to generate entirely new content. It doesn’t just answer questions; it composes emails, summarizes technical manuals, and proposes solutions in natural language. Foundation models enable this by learning general language and reasoning patterns from large datasets and then applying them flexibly to domain-specific tasks (Figure 1).
Agentic AI builds on that capability. Think of it as GenAI with autonomy. Instead of stopping at insights, it acts within defined boundaries. It can monitor wells, triage problems, analyze potential causes, query SAP for part availability, propose next steps, and notify the right people—all in one loop.
The shift toward agentic AI isn’t about buzzwords. It’s about building AI that operates like a team member: resourceful, tireless and fluent in relevant workflows. That is possible partly because of rapid improvements in foundation models. Early models were prone to generating inaccurate or irrelevant responses, so they required constant human oversight. Today’s foundation models include more built-in safety filters and improved reasoning that allows them to handle a broader set of tasks, but they are far from perfect.
For industrial applications, where accuracy, compliance and reliability are paramount, application-specific guardrails remain essential. These can include techniques such as Retrieval-Augmented Generation (RAG), which forces the AI to base its output on trusted databases; structured prompt engineering to constrain outputs; validation layers that check AI outputs against trusted data sources; and human-in-the-loop review steps. The goal is to ensure that AI supports engineering workflows with consistent, auditable results rather than introducing new risks or errors.
FIGURE 1
How Foundation Models Work
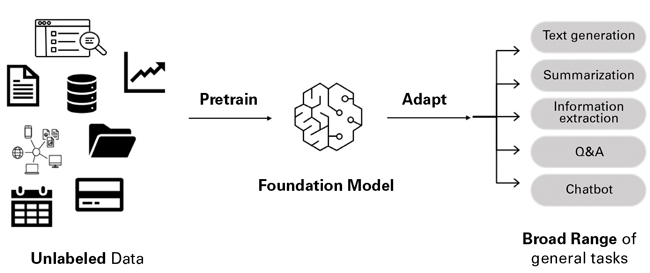
With thoughtfully-designed controls, the payoff for deploying AI in oil and gas environments can be transformative. Production engineers exemplify how much impact it can have, as intelligent solutions automate routine tasks and enhance productivity, allowing the engineers to focus on strategic, high-value initiatives that drive innovation.
Oil and gas upstream operations generate mountains of data, including structured data such as sensor readings and production logs, as well as unstructured data such as PDFs, reports and field tickets. Until now, extracting value from the sea of unstructured data required time-consuming and often tedious work. Generative AI changes that. It can:
- Read and interpret decades of well files;
- Summarize regulatory filings;
- Pull key performance indicators from SCADA and enterprise resource planning systems; and
- Provide instant answers in natural language.
More importantly, it can do this at scale, 24/7. The value? Time. Precision. And the chance to stop being buried in data and start being freed for higher-value engineering work.
How Agentic Assistants Help
Let’s go back to our Permian Basin production engineer. Depending on her company’s size, she might be responsible for hundreds of wells, far too many for her to manage using manual processes. Here is what a system that combines generative and agentic AI could do on her behalf:
- Monitor production, continuously checking each well’s output against targets;
- Identify underperforming wells, then pull historical production data, surface and downhole sensor logs, and recent workover records for those wells to diagnose likely causes (e.g., paraffin build-up or pump wear);
- Query ERP systems for available parts, estimate costs, and lay out potential solutions;
- Draft a one-pager for leadership and send a task update to field crews.
These aren’t futuristic dreams. They are achievable now, combining what GenAI does best (reading, summarizing and generating content) with what Agentic AI adds (taking logical next steps).
Assistant actions (like writing a report or summarizing a regulation) and utility actions (like querying SQL, looking up part availability, or triggering a notification) are all part of the same workflow. By offloading many of these actions to a tireless machine, teams move faster, make smarter decisions, and mitigate the risk of burnout. Agentic AI can automate key steps across production monitoring, diagnosis, recommendations and communications, enhancing team productivity (Figure 2).
Preparing for Implementation
An operator doesn’t need a team of PhDs or a moonshot budget to get started with agentic AI. For most oil and gas producers, the path forward is grounded in operational reality. Here is a practical, step-by-step approach tailored for upstream independents.
FIGURE 2
How Agentic AI Simplifies Well Workover Decisions
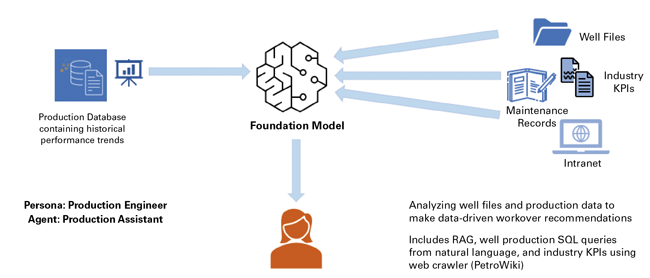
First, map the company’s data ecosystem. Take account of all the data the company collects, including structured data from SCADA systems, historians, ERP systems and daily production logs, as well as unstructured data, such as PDFs of well files, field tickets, maintenance reports and regulatory filings. For each data point, identify where it lives, whether it is stored in SharePoint, local drives, cloud repositories or paper archives.
Getting this baseline is key. It’s impossible to automate something unless you know it exists. With that in mind, conduct a quick audit by function—production, maintenance, compliance—to map out data sources.
The next step is to address the biggest bottleneck in AI adoption: messy data. A GenAI model is only as good as what it learns from, so it’s important to clean up existing data by fixing formatting inconsistencies and correcting or deleting outdated records, duplicates, and bad sensor tags. In the process, standardize by adopting consistent units, naming conventions and file structures across assets.
It’s also important to add metadata tags, or “data about the data,” such as the ID for the asset where the data was collected, the date collection took place and the location. This information makes documents retrievable with GenAI tools.
Cleaning up and enriching data can be time-consuming. Operators should start with their highest-value data sets, which likely include well production reports, downtime logs and maintenance histories.
Starting Small
Instead of aiming for grand AI strategy, companies should focus on addressing pain points their team already faces. Possible use cases include:
- Automating daily well variance reports by tasking GenAI with summarizing deviations and proposing potential causes;
- Accelerating data retrieval by creating a natural language chatbot that lets engineers ask questions like, “Which wells dropped more than 10% in production last week?”; or
- Simplifying compliance by dispatching an AI assistant to summarize and contextualize regulatory PDFs or long equipment manuals.
Keep use cases narrow, impactful and easy to measure. This ensures quick wins and team buy-in.
Once an initial use case has been identified, it’s time to deploy AI with guardrails in place. In almost any situation, it’s best to start with proven foundation models from cloud services, AI research companies, and open source initiatives. These established solutions eliminate the need to build from scratch, providing reliable infrastructure and tools for AI model deployment across different use cases and industries.
For security, companies should limit what the AI can see or act on based on the user’s role (e.g., operations versus leadership). It’s also wise to keep humans in the loop. The AI can recommend actions, such as sending a work order, but before it takes those actions, someone needs to review and approve them.
Even then, it’s useful to document everything. Implement logs for AI outputs and actions to ensure auditability and traceability.
Proving Value
After the initial deployment, measure the value before scaling. There is no need to prove AI works in general. Instead, define KPIs that align with field practices and focus on those. Those KPIs might include:
- Time saved: How many hours did GenAI free up for engineers or field crews?
- Production uplift: Was deferred production avoided through faster diagnostics?
- Downtime reduction: Did early detection of potential failures lead to fewer equipment outages?
- Adoption metrics: Are engineers actually using the tools?
Once the pilot proves successful, apply the learnings to more use cases. Those might include field-wide variance analysis, workover planning, or even training new engineers with support from AI-curated manuals.
Remember that GenAI is not a project. It’s a capability and powerful tool. Build it into how a field works, one step at a time. AI has limitations, but it can deliver huge time savings by automating tasks that primarily require judgments based on historical or easily retrievable information (Figure 3).
The time required to implement an AI-augmented workflow depends on complexity and data readiness. Simple use cases, such as automating variance reports or summarizing documents, can typically be piloted in two to four weeks. More integrated use cases, such as drafting workover orders or correlating SCADA data with maintenance records, often take six to 12 weeks because they require more intense data integration, validation and testing. Advanced scenarios, such as AI-assisted simulations or closed-loop recommendations, may require three to six months, as they need rigorous data preparation, tighter guardrails, and iterative validation with field teams.
FIGURE 3
The Power of Agentic Automation
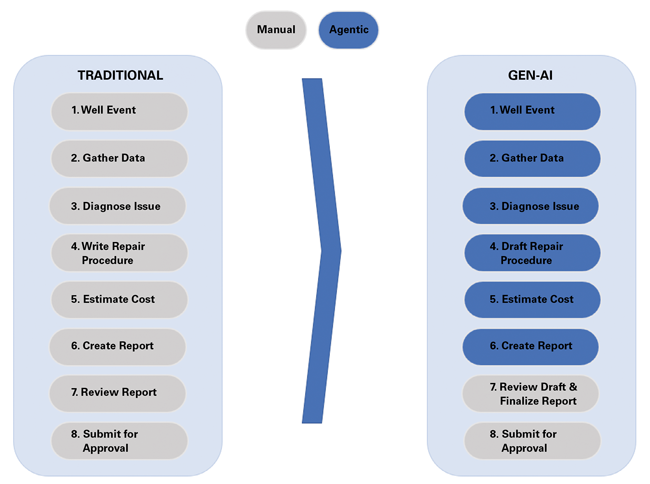
Starting with quick wins helps build trust and lays the foundation for scaling to more sophisticated applications.
Past Success
Applying GenAI and agentic AI to exploration and production workflows is well past the theoretical stage. Many companies are already doing it.
For example, a U.S. operator with assets in several shale plays recently implemented generative AI to transform how its production teams manage data and make decisions. The AI-powered system monitors thousands of SCADA signals in real time, automatically flags anomalies, and generates natural-language summaries that connect production trends to specific operational issues.
Unlike traditional dashboards, the AI operates as a conversational assistant with memory and context retention, allowing engineers and field personnel to interact with it naturally. For example, an engineer can ask, “Why did the Johnson No. 3 well underperform this week?” and follow up with, “Have we seen similar patterns in nearby wells?” or “What artificial lift adjustments were made recently?”
The system draws on historical data, benchmarked performance, and current field conditions to provide grounded, context-aware responses. This conversational capability reduces the time spent navigating complex data interfaces or compiling reports, while enabling faster, more informed operational decisions. The result: quicker anomaly resolution, reduced downtime, and more time for engineers to focus on optimization rather than data hunting.
Addressing Risks
No technology is without challenges. For AI, those risks fall into two categories: operational and technical.
The operational risks begin with data quality. When data is missing, inconsistent or outdated, AI can produce misleading recommendations. To minimize that possibility, establish rigorous data governance protocols and automatic validation routines to ensure that data remains accurate and comprehensive.
The second operational risk relates to trust. Users may hesitate to rely on AI outputs if those outputs seem to come from a black box. Ideally, companies should build transparency by using explainable models and interfaces that not only show outcomes, but also demonstrate how the AI reached those outcomes and provide clear provenance for data sources.
The third operational risk relates to security and privacy. Without the right guardrails, AI could enable data breeches or misuse sensitive operational data. For protection, enforce role-based access, encrypt data in motion and at rest, and implement audit trails.
Finally, it’s worth emphasizing that AI, like any technology, needs to be adopted for it to have any value. Unless teams receive appropriate training, adoption may stall. Even with it, it’s important to invest in change management and offer user-friendly interfaces tailored to field operations.
The four operational risks outlined above come alongside a technical risk that almost anyone who has played around with older, consumer-oriented AI models will recognize: Hallucinations, or situations where the AI generates plausible but incorrect content. Retrieval augmented generation frameworks can minimize hallucinations by mandating that AI fetches information from verified databases or document repositories before generating a response. The idea is to ground outputs in trusted documents and databases.
As AI adoption grows, cost can become a concern. Despite their creators’ optimization efforts, foundation models can be expensive to run. To control costs, companies should monitor usage, set thresholds and choose right-sized models for tasks.
Managing these risks takes care, but the reward justifies the effort. Generative AI and agentic AI are not just tech trends—they’re transformative tools for upstream production teams. By pairing human expertise with machine efficiency, companies can unlock a new way of working where engineers do more engineering and less administration. Where decisions come faster. And where every well, every sensor and every workover plan is part of a continuous, intelligent loop.
Start small. Think big. And most importantly, design AI that fits into the life of the field engineer—not the other way around.
Editor’s Note: The views expressed in this article are the author’s and do not necessarily reflect those of Amazon Web Services Inc. or its affiliates.

SHANKAR NARAYANAN leads technology partnership sales at Amazon Web Services, specializing in asset performance management and process control solutions. With more than 15 years of experience in the energy industry, Narayanan has spearheaded numerous digital transformation initiatives, driving efficiency and productivity for Fortune 500 energy companies. He has held multiple leadership positions at Baker Hughes and General Electric. Before joining AWS, he led global partnerships and sales for Bently Nevada, a Baker Hughes business that helps companies monitor, maintain and optimize assets.
For other great articles about exploration, drilling, completions and production, subscribe to The American Oil & Gas Reporter and bookmark www.aogr.com.